
💡 En résumé : Pour programmer un déplacement case par case dans une grille (jeu vidéo, robotique, simulation), l’algorithme fondamental est la Recherche en Largeur d’abord (BFS). Il explore progressivement toutes les cases atteignables depuis un point de départ, en garantissant de trouver le chemin le plus court (en nombre de cases). Pour des besoins plus avancés (coûts variables, recherche plus rapide), on utilise ses dérivés : l’algorithme de Dijkstra (pour les poids) et A* (avec une heuristique).
Vous avez une grille, un point de départ, un point d’arrivée et peut-être des obstacles. La question semble simple : comment faire pour que votre personnage, votre robot ou votre unité se déplace de l’un à l’autre, case par case, de la manière la plus efficace possible ? Derrière cette simplicité apparente se cache l’un des piliers de l’algorithmique spatiale, avec des applications directes dans le développement de jeux, la robotique ou la logistique.
La réponse immédiate, celle que vous implémenterez dans 80% des cas, est la Recherche en Largeur (BFS – Breadth-First Search). C’est l’outil de base, robuste et parfait pour les déplacements à coût uniforme (chaque case « coûte » 1 mouvement). Si votre problème est plus complexe (terrains variés, recherche de rapidité), vous vous tournerez vers des algorithmes plus spécialisés comme Dijkstra ou A*. Commençons par décortiquer le BFS, car tout part de là.
Le BFS : L’algorithme fondamental du déplacement sur grille
Imaginez une tache d’encre qui s’étend uniformément dans l’eau. Le BFS fonctionne exactement sur ce principe : il explore la grille par « couches » successives de distance égale depuis la source. On marque la case de départ avec la distance 0. Puis, on regarde ses 4 voisins directs (haut, bas, gauche, droite). Ceux qui sont libres et non visités reçoivent la distance 1. Ensuite, on examine les voisins des cases à distance 1 pour leur attribuer la distance 2, et ainsi de suite.
Ce processus garantit deux choses capitales :
- ✅ Il trouve toujours un chemin s’il existe.
- ✅ Le chemin trouvé est le plus court en nombre de cases (parcours minimal).
Concrètement, on utilise une file d’attente (queue) pour gérer l’ordre d’exploration. Voici le squelette logique en pseudo-code :
1. Créer une file d'attente Q.
2. Marquer la case de départ comme visitée (distance 0) et l'ajouter à Q.
3. Tant que Q n'est pas vide :
a. Prendre la première case C de la file.
b. Pour chaque voisin V de C (haut, bas, gauche, droite) :
- Si V est dans la grille, n'est pas un obstacle et n'est pas visité :
* Marquer V comme visité (distance de C + 1).
* Enregistrer que C est le "parent" de V (pour reconstruire le chemin).
* Ajouter V à la fin de la file Q.
4. Le chemin optimal est reconstruit en remontant de la case d'arrivée à la case de départ via les parents.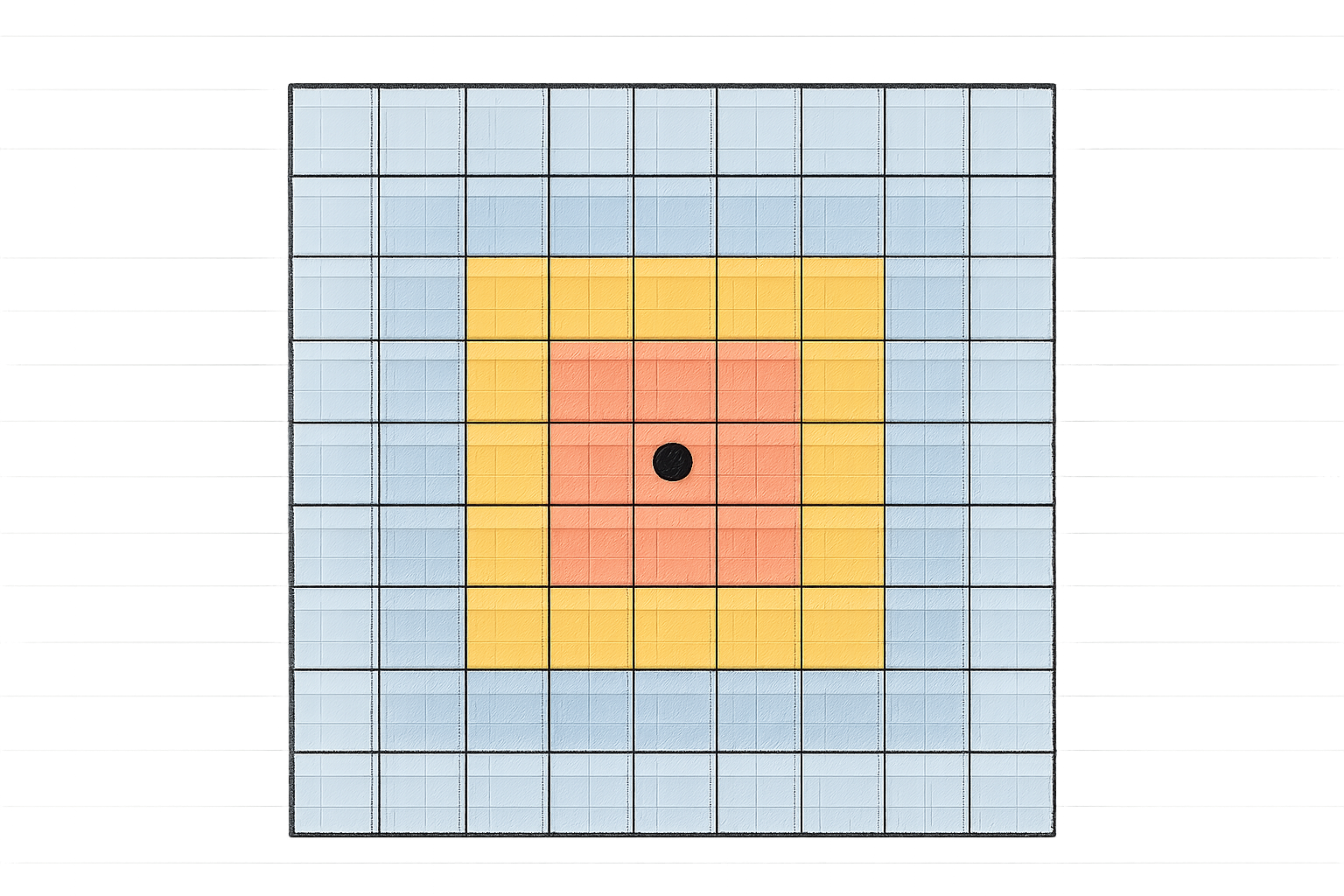
🛠️ Astuce de Pro (NathTrig) : Avant de coder, faites le test sur papier quadrillé. Numérotez les cases à la main en partant du départ. Cette gymnastique visuelle vous fait intégrer la logique du BFS mieux que n’importe quel tutoriel. C’est comme ça que je vérifiais les algorithmes sur ma vieille Casio programmable.
Du BFS à des Algorithmes Plus Puissants
Le BFS est parfait quand le monde est uniforme. Mais dans la réalité, toutes les cases ne se valent pas. Traverser une plaine n’a pas le même coût que gravir une montagne ou traverser un marais. C’est là qu’interviennent les extensions naturelles du BFS.
L’algorithme de Dijkstra : Gérer les terrains à coût variable
Dijkstra est au BFS ce qu’un pèse-lettre est à un compteur d’unités. Au lieu de considérer que chaque déplacement coûte 1, il fonctionne avec des coûts (ou poids) arbitraires sur chaque arête (ici, le passage d’une case à sa voisine).
La logique change légèrement : on n’utilise plus une simple file, mais une file de priorité (priority queue) qui traite en premier la case avec la distance totale la plus faible depuis l’origine. On ne se contente plus de marquer « visité », on met à jour en permanence la meilleure distance connue pour chaque case.
Cette vidéo de Maths+1 explique visuellement en 5 minutes le principe de l’algorithme de Dijkstra pour trouver les trajets minimaux, un concept directement transposable à nos grilles de déplacement.
L’algorithme A* : La recherche heuristique pour gagner en vitesse
Quand la grille est grande, explorer dans toutes les directions comme le fait Dijkstra peut être très lent. A* (A-star) ajoute une heuristique – une estimation intelligente de la distance restante jusqu’à la cible (souvent la distance « à vol d’oiseau » de Manhattan ou Euclidienne).
Au lieu de prioriser uniquement la distance parcourue, A* priorise la somme : distance parcourue + estimation restante. Cela guide l’exploration préférentiellement vers la cible, réduisant radicalement le nombre de cases à visiter. C’est l’algorithme de prédilection pour les IA de jeux vidéo dans les labyrinthes ou les mondes ouverts.
📊 Tableau Comparatif : Quel Algorithme Choisir ?
| Algorithme | Avantages | Inconvénients | Usage Typique |
|---|---|---|---|
| BFS Simple | Simple à implémenter. Optimal pour coût uniforme. | Mémoire élevée sur grandes grilles. Lent sans objectif. | Jeux tactiques au tour par tour, déplacement avec PM limités. |
| Dijkstra | Gère des coûts variables par case (herbe, route, montagne). | Plus lent que BFS pour coûts uniformes. | Simulations de trafic, robotique avec terrains complexes. |
| A* | Très rapide avec une bonne heuristique. Standard dans l’industrie. | Heuristique mal choisie = non-optimalité ou lenteur. | IA de jeux (STRATEGIE, RPG), pathfinding en temps réel. |
Pièges à Éviter et Bonnes Pratiques d’Implémentation
Implémenter ces algorithmes n’est pas exempt d’écueils. Sur les forums comme OpenClassrooms, les mêmes erreurs reviennent souvent.
- 🚫 Les boucles infinies : Oublier de marquer une case comme « visitée » dès son insertion dans la file. Résultat ? On la traite à l’infini.
- 🚫 L’oubli des limites : Ne pas vérifier
if (x >= 0 && x < largeur && y >= 0 && y < hauteur)avant d’accéder à la grille ⇒ plantage garanti (ArrayIndexOutOfBoundsException en Java). - 🚫 La gestion des obstacles : Les cases obstacles doivent être simplement ignorées lors de l’exploration des voisins.
- 🚫 Les diagonales : Le BFS de base n’explore que les 4 directions cardinales. Pour inclure les diagonales (8 directions), il faut ajouter 4 autres vecteurs de déplacement (e.g., [-1, -1], [-1, 1]…). Attention, la distance n’est alors plus le simple nombre de cases !
Pour visualiser et déboguer, rien ne vaut un affichage simple de la grille des distances dans la console, ou mieux, une librairie graphique comme Pygame en Python pour voir l’exploration en temps réel.
FAQ : Réponses aux Questions Fréquentes
Quand dois-je choisir BFS plutôt que A* pour mon jeu ?
Choisissez BFS si votre monde est une grille simple où chaque déplacement a un coût identique (1 point de mouvement) et que vous avez besoin de connaître toutes les cases atteignables à une distance donnée (ex : zone d’effet d’un sort, déplacement limité). A* est nettement supérieur dès que vous avez un point d’arrivée précis et une grande carte, car il sera beaucoup plus rapide en se dirigeant directement vers le but. Pour un jeu de stratégie au tour par tour sur petite carte, le BFS peut suffire. Pour un RPG en temps réel, A* est indispensable. Une discussion approfondie sur ce choix est disponible sur ce forum OpenClassrooms.
Comment gérer des obstacles dynamiques qui apparaissent pendant le déplacement ?
Pour des obstacles dynamiques, l’algorithme doit être recalculé (replanifié) à partir de la position courante lorsque l’obstacle est détecté. Des algorithmes comme D* Lite sont des variantes de A* spécialement conçues pour être efficaces dans ces replanifications successives, en réutilisant les calculs précédents. En robotique, c’est un challenge courant. Une approche simplifiée consiste à exécuter A* à nouveau depuis la position actuelle sur la grille mise à jour. La modélisation du problème en graphe, comme expliqué sur Ecole Robots, est la première étape pour envisager cette dynamique.
Peut-on utiliser ces algorithmes pour des déplacements en diagonale ?
Absolument. Il suffit d’élargir la définition de « voisin ». Au lieu de 4 directions (haut, bas, gauche, droite), utilisez les 8 directions (en ajoutant les quatre diagonales). Cependant, cela introduit une subtilité : la distance métrique change. Le « chemin le plus court » en nombre de mouvements n’est plus le même. Souvent, on utilise un coût de √2 (environ 1.41) pour les déplacements diagonaux dans Dijkstra ou A* pour refléter la distance géométrique réelle. Dans un BFS simple, une diagonale compte pour 1 mouvement, tout comme un déplacement orthogonal.
Mon algorithme boucle à l’infini ou plante. Quelles sont les erreurs les plus courantes ?
Trois fautes classiques : 1) Oublier de marquer la case comme visitée avant de l’ajouter à la file, ce qui permet de l’y remettre indéfiniment. 2) Ne pas vérifier les bornes de la grille avant d’accéder à un tableau, causant une erreur d’indice. 3) Mauvaise gestion de la file de priorité dans Dijkstra/A* : ne pas mettre à jour la priorité d’un nœud déjà présent mais atteint par un chemin meilleur. Utilisez un affichage de débogage pour imprimer la grille des distances à chaque étape clé. Le tutoriel de Dim-MathInnov insiste sur ces points de vigilance.




